Principal Investigator (PI): John Readey: The HDF Group
Co-Investigators (Co-PI): Andrew Michaelis: NASA Ames; Jordan Henderson: The HDF Group
Much of NASA’s Earth observation data can be downloaded in a format called Hierarchical Data Format 5 (HDF5). HDF 5 is a file format designed by the National Center for Supercomputing Applications that enables users to store and manipulate scientific data across diverse operating systems and machines.
This approach has worked well for the nearly 30 PB of Earth data stored on NASA’s physical servers. However, with the launch of new missions, the volume of data in the Earth Observing System Data and Information System (EOSDIS) archive is expected to grow by almost 50 PB per year to more than 246 PB by 2025. Moving the EOSDIS archive to the cloud has the potential to improve the accessibility and management of NASA Earth observation data by bringing data “close to compute” in a way that is efficient, scalable, and easy to use. Potentially, researchers will be able to access large amounts of data using the same applications they use on their individual machines, without worrying about storage or computing constraints.
However, HDF5 and other file types aren’t optimized for the cloud, which works best with object-based storage. In object-based storage, data are stored as objects that are identified with a key rather than as files within a file system. This saves space and time. HDF5 files are stored as S3 (Simple Storage Service) objects, but the HDF5 library can’t read directly from these files.
To solve these challenges, the HDF Group created Highly Scalable Data Service (HSDS), which is a REST-based service for reading and writing HDF5 data. This service provides all the functionality that was traditionally provided by the HDF5 library but in a manner that can utilize cloud based storage (e.g. AWS S3) and is accessible by any HTTP client.
In order to be scalable, HSDS is implemented as a set of Docker containers. By increasing the number of containers (this is possible by running a cluster-based system such as Kubernetes), an arbitrary number of clients can be supported. In addition to supporting more clients, individual requests can be parallelized by the service taking advantage of multiple containers to read and write data to individual portions of the dataset. The following diagram illustrates the system architecture:
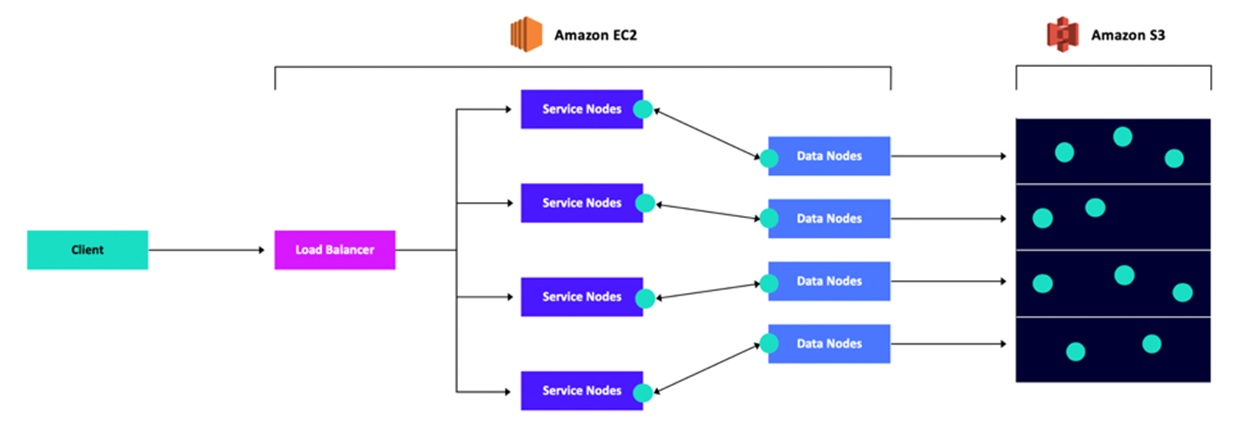
HSDS service not only provides functional equivalents to the HDF5 library (e.g. compression, hyperslab and point selection, objects organized in a directed graph), the service also supports many features not yet implemented in the library. For example:
- Multi-reader/multi-writer support
- Compression for datasets using variable length types
- SQL-like queries for datasets
- Asynchronous processing
In addition to the HSDS service we have also developed a set of client library and utilities:
- REST VOL—HDF5 library plug in that clients can use to connect with HSDS
- H5pyd—Python package for clients to connect with HSDS
- HS CLI—Command line utilities for import, export, listing content, etc.
Using the REST VOL (for C/C++/Fortran applications), or h5pyd (for Python scripts), existing code can be easily re-purposed to read/write data from the cloud.
The command line utilities provide equivalents to standard Linux and HDF5 applications such as cp, chmod, h5ls, etc.
Outside of the NASA ACCESS project, there is also created a commercial version of HSDS called Kita™. Kita includes:
- Kita™ Lab—a Jupyter Lab based collaborative environment
- Kita™ Server—AWS Marketplace product
- Kita™ On Prem—Solution for deployments to non-cloud datacenters
To learn more visit the:
In the News: